步骤1
先获取cached和uncached的读取时间,根据这个两个时间设置一个阀值
下面的代码是循环ESTIMATE_CYCLES次后取读取时间的平均值,再计算阀值
1 |
|
这是某次运行时候计算的结果
cached = 30, uncached = 416, threshold 111
可以看到 uncached的读取实践明显高于cached,我们可以根据有无cached进行推测一些东西
步骤2
步骤2是将我们想要读取的值读取到eax(实际是al,编译后查看汇编是movzx eax, byte ptr [rdi],其中rdi就是我们要读取的addr),这时候重要的操作来了,我们获取到的al只是作为target数组的索引(这里的target即target_array数组),由于推测执行和乱序执行,target+ rax * 4096这个地址的值就被缓存下来了(这是重点)
关键代码
1 | ".rept 300\n\t" |
为了方便,也贴一下ida看到的汇编代码
1 | ...... |
步骤3
这时候我们再尝试测试读取target+ i * 4096,一旦发现这个读取时间小于阀值(threshold),那么就证明这时候的i就是之前读取出来的al的值了,即从侧面知道了之前读取的值了
作者代码如下:
1 | static int cache_hit_threshold; |
我改成直接读取&target_array[i * TARGET_SIZE];也是可以的,修改如下
1 | void check(void) |
其中mix_i就是真正泄露出来的值,而hist[mix_i]是所谓的分数,即这个值命中了几次,因为推测执行和乱序执行不一定每次都能执行到那里了,所以对于读取每一个byte,都循环执行了1000次,当然每次执行前都要将target_arrayflush掉
1 | for (i = 0; i < 256; i++) |
所以要提高泄露数据的成功率,可以增加读取每个byte时候的循环次数
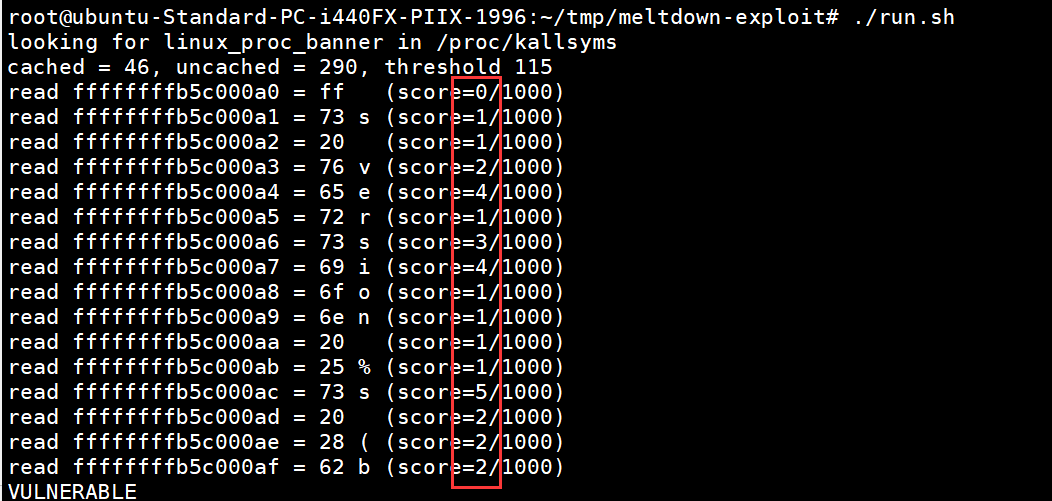
下面可以看到1000次成功0到5次
references
https://weibo.com/ttarticle/p/show?id=2309404192925885035405
https://github.com/paboldin/meltdown-exploit/blob/master/meltdown.c


