Binary-only fuzzing 的一些常见问题
QEMU是AFL++支持的后端之一,用于Binary-only的模糊测试,这是通过patch QEMU来执行原始二进制文件,以收集覆盖率信息。
此外,针对QEMU模式,可以配置不同的环境比那里来优化模糊测试的性能和覆盖率。
插桩相关:
- AFL_INST_LIBS:设置 AFL_INST_LIBS 会导致qemu翻译器对任何动态链接库中的代码进行插桩(特别是包括glibc在内的库)。比如设置AFL_INST_LIBS=1即可。
- AFL_QEMU_INST_RANGES:您可以使用 AFL_QEMU_INST_RANGES=0xaaaa-0xbbbb,0xcccc-0xdddd 来仅插桩特定的内存位置,或者是特定的库 ,值得注意的是排除范围优先于包含范围的变量的。
变异相关:
- AFL_CUSTOM_MUTATOR_LIBRARY,这个设置自定义的共享库路径,一般里面实现了afl_custom_fuzz()去生成样本
- AFL_CUSTOM_MUTATOR_ONLY,假如这个设置了,就只是用上面的库进行变异,其他默认的变异策略都不使用
执行相关:
- AFL_ENTRYPOINT:允许您指定二进制文件的特定入口点(这对性能非常有好处!)。入口点以十六进制地址的形式指定,例如, 0x4004110 。请注意,地址必须是基本块的地址。
- AFL_QEMU_PERSISTENT_ADDR:当目标为i386/x86_64时,可以使用 AFL_QEMU_PERSISTENT_ADDR=start addr 指定需要执行persistent loop的函数地址。
- AFL_QEMU_PERSISTENT_HOOK:(persistent hook)会在每次持久迭代(在START处开始)执行一个在共享对象中定义的函数,您可以通过指定AFL_QEMU_PERSISTENT_HOOK=/path/to/hook.so来指定共享对象的路径。
- AFL_DISABLE_TRIM :设置 AFL_DISABLE_TRIM 告诉 afl-fuzz 不要修剪测试用例。这通常是一个坏主意!
- AFL_DEBUG:会将二进制文件的入口点打印到stderr。如果您不确定入口点是否正确,请使用此选项。但直接使用,例如 afl-qemu-trace ./program 。
- AFL_DEBUG_CHILD :设置 AFL_DEBUG_CHILD 这样可以看到子进程的所有输出,从而更好地发现问题。
从理论到实践有时看起来很乏味,经常会引发一些反复出现的问题,比如:
- 我们希望插桩到哪些代码
- 模糊测试的入口点的最佳选择是什么
- 移动入口点对于测试用例的格式产生什么影响
- 如何利用afl++提供的环境变量,提高fuzzing的性能
学习示例
一个简单的X509解析器
这是一个二进制文件,它接收一个文件名作为输入,并尝试解析相应文件的内容作为X509证书。
学习示例源码:https://github.com/airbus-seclab/AFLplusplus-blogpost/tree/main/src
main函数:调用init初始化,之后将文件作为参数传递给parse_cert函数
parse_cert函数:调用read_file函数读取文件,之后调用base64_decode进行文件解码,最后调用parse_cert_buf
parse_cert_buf函数:使用openssl库的d2i_X509进行解析,尝试获取CN并打印。
注:在证书中,”CN” 代表 “Common Name”,即 “通用名称”。它是用于标识证书(如SSL证书)所关联的实体(例如网站、服务器等)的一个字段。通常情况下,CN字段会包含一个域名(或者IP地址),用于指示证书所属的主体实体的名称。在SSL证书中,CN字段通常用于验证证书是否与访问的域名匹配,以确保通信的安全性。
原作者故意在函数中留了一个缓冲区溢出漏洞:strcpy(cn, subj); // Oops
1 | int parse_cert_buf(const unsigned char *buf, size_t len) { |
而且作者在主函数的开头故意添加了一个虚拟的 init 函数,以模拟一个初始化阶段,这会花费一些时间并使目标变得缓慢启动,不过才usleep50毫秒。
探索目标
在现实生活中,目标显然不像我们上面的X509解析器那样简单。事实上,对于一个只有二进制文件没有源码的目标进行有效的模糊测试,总是要先进行逆向工程,一般有以下阶段:
- 了解目标,它的工作原理,以及它与环境的交互等
- 找到有趣的特征进行研究
- 寻找可能成为模糊测试目标的函数
- 分析上下文、结构体、用户可控的参数等
- 构建一个harness,以适当的参数和模糊输入调用目标函数
- 生成或者收集一个初始语料库,以启动模糊测试
由于上面的示例比较简单,所以不需要花太长时间来找到易受攻击的代码、调用追踪并确定感兴趣的函数就是parse_cert_buf
1 | int __cdecl main(int argc, const char **argv, const char **envp) |
Corpus 语料库
需要收集目标程序期望的输入格式的文件,由于示例是一个证书解析器,那就可以用openssl生成一个证书:
1 | $ openssl req -nodes -new -x509 -keyout key.pem -out cert.pem |
1 | 这个命令是使用OpenSSL工具生成自签名的RSA密钥对和X.509数字证书文件的命令。下面是对每个选项的解释: |
作者把—–BEGIN CERTIFICATE—–和—–END CERTIFICATE—–以及前后空格给去掉当作
预处理语料库
在使用这个语料库之前,我们可以进行预处理
- 只保留不同执行路径的输入样本(使用 afl-cmin )
- 尽量减小每个输入样本的大小,以保留其独特的执行路径,同时使其尺寸尽可能小(使用 afl-tmin )。这将使变异更加有效,因为文件样本小了。
作者将其写成了脚本build_corpus.sh:先进行cmin,再缩减样本大小tmin
1 | #!/bin/bash |
其中afl_config.sh 文件如下:
1 | $ cat afl_config.sh |
插桩
默认设置(step 0)
通过默认的形式启动AFL++的QEMU模式,目标的所有基本块都被插桩,共享库不包含在插桩中。
1 | #!/bin/bash |
我们可以在下面的不断优化中查看执行速度的变化
在我的机器上,这个默认模式,速度大概是18每秒
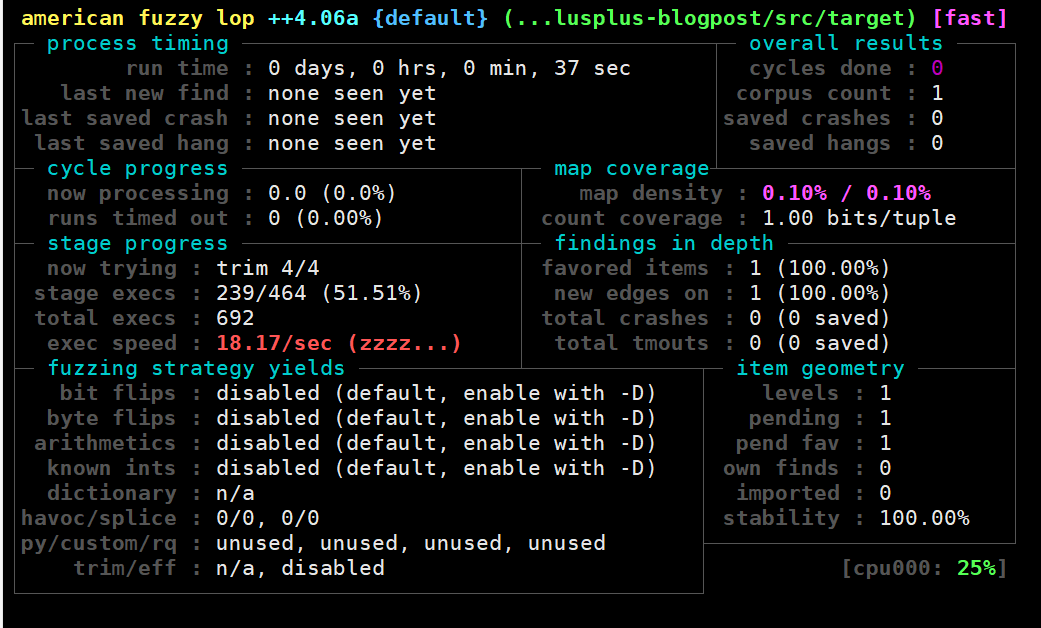
插桩调优(step 1)
对于插桩的调优,可能有以下原因:
- 对于导入库的覆盖路径情况感兴趣
- 要排除已经进行过安全测试的库的特定部分
- 对整个库的二进制文件进行插桩可能会降低执行速度
如果需要调优,可有下面变量可用
- AFL_INST_LIBS
- AFL_QEMU_INST_RANGES
- AFL_CODE_START
- AFL_CODE_END
在上面证书解析的例子中,parse_cert_buf 的插桩很重要,但是对于main的插桩就不那么相关了,还有共享库libssl.so
我们可以通过AFL_QEMU_INST_RANGES来将插桩限制在想要关注的函数上,即parse_cert_buf的第一条指令到最后一条指令
注意:可以使用 AFL_CODE_START 和 AFL_CODE_END 来完成这个操作。然而, AFL_QEMU_INST_RANGES 更加灵活,因为它允许指定多个范围进行插桩。
作者写好了脚本来设置
1 | # The base address at which QEMU loads our binary depends on the target |
inst_start就是QEMU_BASE_ADDRESS+函数文件内偏移
inst_end就是函数文件内偏移+函数大小
作者给的find_func函数有点难理解,下面的其实更好理解,双引号是正则匹配,后面是输出规则
1 | function find_func() { |
可以使用下面的更简单
1 | objdump -t "$target_path" | grep $1 | awk '{print "0x"$1, "0x"$5}' |
上面脚本可添加echo $fuzz_func_addr $fuzz_func_size可以输出获取的值,看看是否正确
1 | $ ./find_func.sh parse_cert_buf |
之后启动afl的时候,通过启用AFL++-QEMU的调试模式( AFL_DEBUG ),我们可以检查插桩范围是否与我们设置的一样
1 | $ AFL_DEBUG=1 ./fuzz.sh | grep Instrument |
Entrypoint 入口点(step 2)
在模糊测试时,AFL++会运行目标程序直到达到特定地址(AFL入口点),然后从该地址fork进行每一次迭代。默认情况下,AFL入口点被设置为目标程序的入口点(在我们的示例中, target 的 _start 函数)。
1 | $ AFL_DEBUG=1 ./fuzz.sh | grep entrypoint |
可以看到,确实是1320偏移
1 | .text:0000000000001320 public _start |
在某些情况下(如我们的示例中),程序的初始化阶段可能需要一些时间。由于每次迭代都要进行初始化,这直接影响了模糊测试的速度。这正是 AFL_ENTRYPOINT 选项旨在解决的情况。
这样的话我们可以跳过初始化阶段,直达AFL_ENTRYPOINT 地址,停在AFL_ENTRYPOINT地址与fuzzer同步,让fuzzer对目标进行快照,之后便可有在AFL_ENTRYPOINT之后继续执行。
对于上面的例子,init函数是确定性的,也无需模糊测试,所以可以将AFL_ENTRYPOINT 设置为 parse_cert
parse_cert是1550偏移
1 | $ ./find_func.sh parse_cert |
通过AFL_ENTRYPOINT环境变量设置一下即可
1 | read fuzz_func_addr fuzz_func_size < <(find_func "parse_cert") |
可以看到确实更改了入口点

查看现在的速度,已经提升到600+,原始作者更牛逼,直接1000+,估计他的cpu性能更好
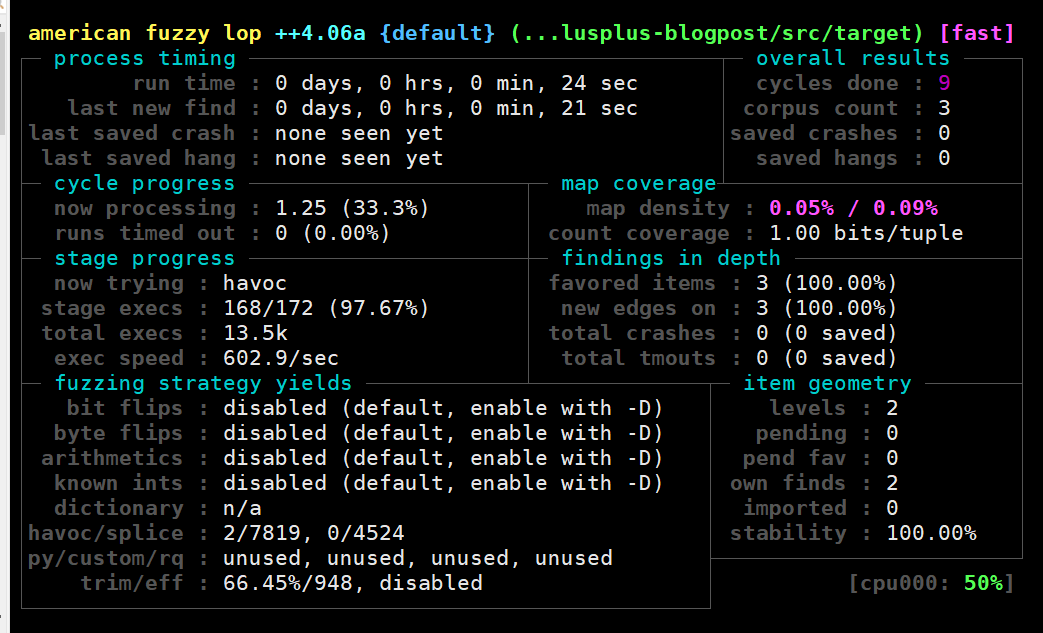
Persistence
Persistent mode(step3)
“持久模式”是AFL++的一个功能,允许它在每次迭代时避免调用 fork 。相反,它会在子进程到达特定地址( AFL_QEMU_PERSISTENT_ADDR )时保存其状态,并在到达另一个地址( AFL_QEMU_PERSISTENT_RET )时恢复该状态。
注意:如果没有设置 AFL_QEMU_PERSISTENT_RET ,可以使用 AFL_QEMU_PERSISTENT_RETADDR_OFFSET 。如果没有设置这些值,AFL++将在到达第一个 ret 指令时停止(仅当 AFL_QEMU_PERSISTENT_ADDR 指向函数的起始位置时,否则必须手动设置该值)。
“恢复”状态可能意味着“恢复寄存器”( AFL_QEMU_PERSISTENT_GPR )和/或“恢复内存”( AFL_QEMU_PERSISTENT_MEM )。由于恢复内存状态的成本较高,只有在必要时才应该进行;在模糊测试时,要关注稳定性值,以确定是否需要启用此功能。
使用 AFL_QEMU_PERSISTENT_GPR=1,QEMU将保存通用寄存器的原始值,并在每个持久周期中恢复它们。
即使在使用持久模式时,AFL++ 仍会不时调用 fork (每 AFL_QEMU_PERSISTENT_CNT 次迭代,或默认为1000次)。如果稳定性足够高,增加此值可能会提高性能(最大值为10000)。
目标中循环越稳定,您可以运行的时间就越长;循环越不稳定,循环计数值就应该越低。一个较低的值可以是100,最大值应该为10000。默认值是1000。可以使用AFL_QEMU_PERSISTENT_CNT来设置此值。
以上面的例子为例
在上面的例子,以通过将 AFL_QEMU_PERSISTENT_ADDR 设置为与 AFL_ENTRYPOINT 相同的值(即 parse_cert 函数的地址)来开始。这样,AFL++将恢复进程到在读取输入文件内容之前的状态。
1 | read fuzz_func_addr fuzz_func_size < <(find_func "parse_cert") |
在这个例子中,稳定性保持在100%而无需恢复内存状态,因此我们只设置 AFL_QEMU_PERSISTENT_GPR 。我们还将 AFL_QEMU_PERSISTENT_CNT 增加到最大值,因为这不会对我们的稳定性产生负面影响。
下面可以看到Persistent也设置为1660偏移, gpr开启
1 | $ AFL_DEBUG=1 ./fuzz.sh | grep Persistent |
再看看此时的速度是接近6000,速度有了10倍增长
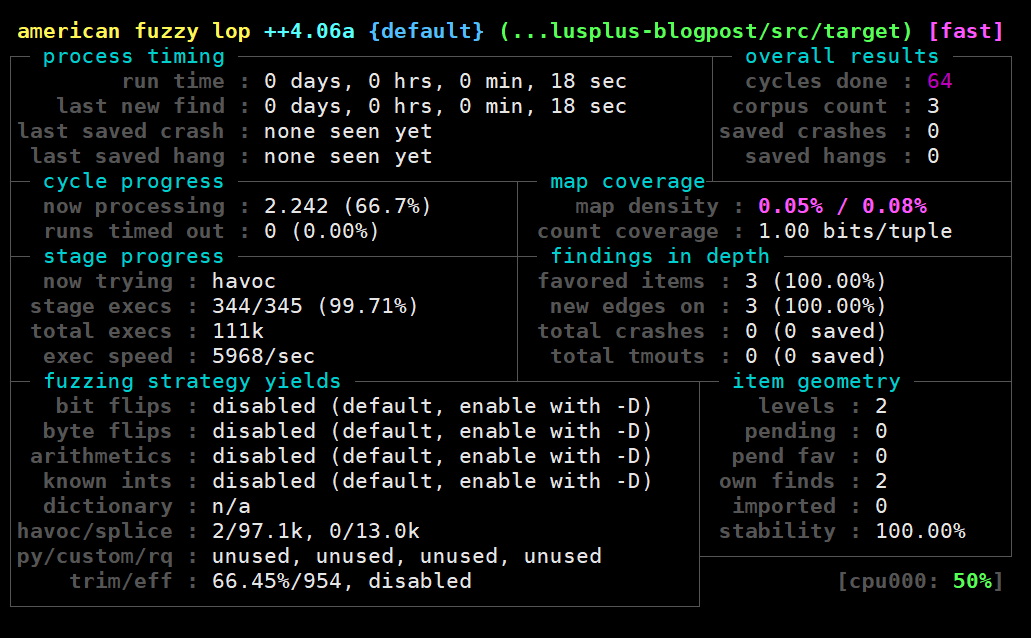
In-memory fuzzing(step 4)
尽管使用了持久模式,但在达到模糊函数之前,我们的目标仍然会执行一些不必要的操作,尤其是打开和读取由模糊器生成的文件的内容。
我们可以使用“内存模糊测试”来跳过这一步骤,直接从模糊测试器的内存中读取输入!
为了做到这一点,我们必须实施一个“hook’”。作者说这个源码比较简单,源码地址
定义了一个 afl_persistent_hook_init 函数,它声明了我们是否要使用内存模糊测试
1 | int afl_persistent_hook_init(void) { |
更有趣的是,我们定义了一个函数afl_persistent_hook,可以在每次迭代之前覆盖寄存器值和内存,就在达到 AFL_QEMU_PERSISTENT_ADDR 地址之前。我们所要做的就是覆盖包含要解析的缓冲区的内存,并在正确的寄存器中设置其长度。
1 | #define g2h(x) ((void *)((unsigned long)(x) + guest_base)) |
作者是受afl++的示例启发的: https://github.com/AFLplusplus/AFLplusplus/blob/stable/utils/qemu_persistent_hook/read_into_rdi.c
注意:您可以通过运行 gdb 并在目标函数的开始的地方中断,或直接查看反汇编代码来确定要使用的寄存器。
这个钩子应该被编译为一个共享库,AFL++将在运行时加载它。
要指示AFL++使用我们的hook,我们只需将 AFL_QEMU_PERSISTENT_HOOK 设置为我们 .so 文件的路径:
1 | export AFL_QEMU_PERSISTENT_HOOK="$BASEPATH/src/hook/libhook.so" |
要使用内存模糊测试,需要在迭代过程中跳过read_file的调用,需要修改 AFL_QEMU_PERSISTENT_ADDR ,这里有两个选项:
1、将AFL_QEMU_PERSISTENT_ADDR 设置为 base64_decode 的起始地址。在这种情况下,我们还要对 base64_decode 函数进行模糊测试;
2、或者我们将AFL_QEMU_PERSISTENT_ADDR 设置在 parse_cert_buf 。在这种情况下, base64_decode 将不会被测试。
由于 base64_decode 是由一个我们不想进行模糊测试的可信外部库实现的(在这种情况下是OpenSSL),我们将选择第二个选项。
因此,我们可以将 AFL_QEMU_PERSISTENT_ADDR 移动到 parse_cert_buf 的地址:
1 | read fuzz_func_addr fuzz_func_size < <(find_func "parse_cert_buf") |
修改 AFL_QEMU_PERSISTENT_ADDR 对我们的语料库有影响。事实上,模糊测试器生成的缓冲区现在直接用于 parse_cert_buf (而不是传递给 base64_decode )。这意味着我们需要重建我们的语料库。在我们的情况下,这很容易:我们只需要解码之前语料库中的base64文件,并将它们保存为原始二进制文件。
1 | base64 -d test.cert.b64 > test.cert |
这样我们不再从文件中读取数据,但是目标程序期望从一个文件中读取数据,否则它将立即退出。,所以我们需要创建一个空文件,传递给程序。
1 | int __cdecl main(int argc, const char **argv, const char **envp) |
在Debug模式中也有successfully got fuzzing shared memory
1 | $ AFL_DEBUG=1 ./fuzz.sh | grep AFL |
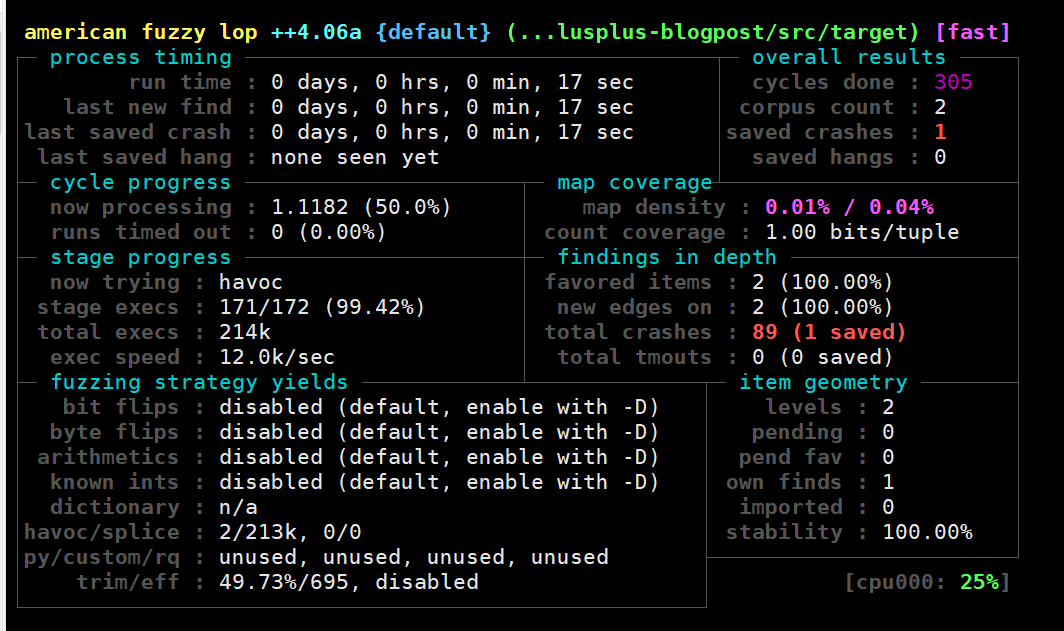
注意:由于执行速度并不是唯一重要的指标,当然你还应该关注其他指标,比如稳定性、新发现的路径、覆盖率等等。
语法感知的变异器(step 5)
动机
回顾一下我们迄今为止取得的成就:
- 使用QEMU来设置AFL++来对一个仅有二进制文件的目标进行模糊测试
- 配置了插桩范围,只覆盖相关的地址
- 调整的AFL++的QEMU模式的入口点,并启用持久模式减少初始化时间,还改用了共享内存fuzzing
在大多数情况下,这样的配置足以运行成功模糊测试,尤其是与多处理器结合的时候。
然而,对于这个例子,我们还决定使用高度结构化的数据格式为输入进行模糊测试。
在这种情况下,引入新的方式来改变输入数据可能会很有趣。
确实,AFL++的另一个可调节的方面是生成和变异逻辑。AFL++内置了一组简单(但非常有效)的变异方法:
- random bit flips; 随机位翻转;
- random byte flips; 随机字节翻转;
- arithmetics; 算术运算;
- 等等
在大多数情况下,这些突变已足够用来探索代码进行模糊测试。但是某些数据格式具有内部约束,如果不满足这些约束,样本将被提前拒绝。
这就是ASN.1的情况,这是我们示例中使用的格式:如果在生成突变时不考虑这些约束,可能会导致大多数样本被目标系统立即丢弃为无效样本,从而无法实现任何增加的覆盖率。这意味着模糊测试活动需要一段时间才能收敛到相关的生成案例,影响fuzzing的效率或者直接导致毫无成果。
为了解决这种情况,AFL++允许用户提供自定义的变异器,以指导模糊测试工具生成更适合的输入。正如官方文档中所详细说明的那样,只要这个变异器实现了所需的API函数,就可以将其插入到AFL++中。
实施
有几种方法可以在AFL++中实现语法感知的变异器,其中之一是AFL++项目中的语法变异器。
然而,由于它不支持ASN.1,我们转而依赖于处理ASN.1的libprotobuf。
我们从官方文档和现有的框架中汲取灵感,构建了AFL++和我们自定义变异器之间的“粘合剂”。
最终实现为 custom_mutator.cpp
实现了以下来自AFL++ API的函数:
- afl_custom_init :初始化我们的自定义变异器;
- afl_custom_fuzz :使用我们的protobuf变异器来改变输入;
- afl_custom_post_process : 对突变数据进行后处理,以确保我们的目标接收到正确格式的输入;
- afl_custom_deinit : 清理一切。
输入格式
确实, afl_custom_post_process 函数发挥着重要的作用:我们的自定义变异器基于libprotobuf,因此需要protobuf数据作为输入。然而,我们的目标只能解析ASN.1数据,因此我们需要将数据从protobuf转换为ASN.1。幸运的是,protobuf变异器已经在 x509_certificate::X509CertificateToDER 中实现了这个功能。
以下是整个过程:
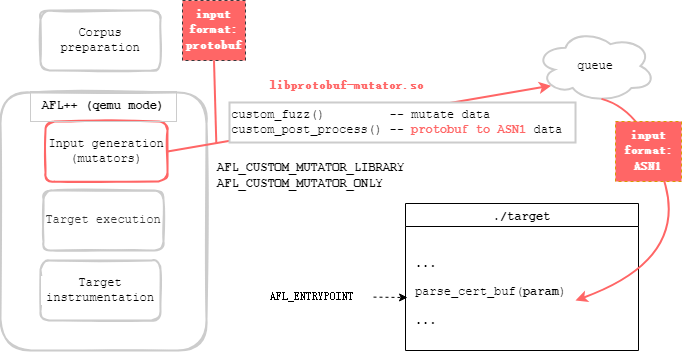
实际就是将输入通过afl_custom_fuzz进行变异,再通过afl_custom_post_process将数据从protobuf转换为ASN.1
和以前一样,我们需要调整我们语料库中文件的格式,以与我们的模糊测试工具相匹配。这一次,我们需要将我们的ASN.1 DER文件转换为protobuf格式。为此,我们实现了一个自定义脚本(asn1_to_protobuf.py)
应用于我们的例子
只需将 AFL_CUSTOM_MUTATOR_LIBRARY 设置为我们 .so 文件的路径
1 | export AFL_CUSTOM_MUTATOR_LIBRARY="$BASEPATH/libmutator.so" |
禁用了AFL++执行的所有默认变异和修剪操作
1 | export AFL_DISABLE_TRIM=1 |
这一次,不是关于提高性能,而是关于深入探索更深层次的路径。在我们的例子中,这是一个非常小的目标,很难衡量这种影响。
然而,通常会通过比较覆盖范围并使用自定义变异器来检查是否达到了新的分支来完成此操作。
然而,您无需在使用自定义变异器和使用默认的AFL++变异器之间做出选择:通过运行多个模糊测试实例,您可以兼得两者的优点,我们将在下一步中讨论这个问题。
(from实践者:由于这个使用了谷歌的proto,编译出了点问题,暂时放弃这个的实践)
多进程(step 6)
这一步是我们将所有内容整合在一起来运行我们的实际模糊测试活动。实际上,在真实的活动中,你不会仅限于在一个核心/线程/机器上进行模糊测试。幸运的是,AFL++可以同时运行多个实例。
在同一台机器上,由于AFL++的设计方式,有一个最大的CPU核心/线程数量是有用的,使用更多的核心会导致整体性能下降。这个值取决于目标,限制在每台机器32到64个核心之间。
需要注意的是,即使在达到这个限制之前,性能的增加也不是成比例的(核心数量翻倍并不意味着每秒执行次数翻倍):需要额外的开销来同步进程。
当运行多个模糊测试实例时,可以通过并行使用各种策略和配置来优化覆盖率。然而,由于该页面主要针对源代码可用的模糊目标,因此对于仅有二进制代码的模糊测试,需要进行一些调整。
Binary-only fuzzing的特殊性
当对源代码可用的目标进行模糊测试时,许多功能(例如ASAN、UBSAN、CFISAN、COMPCOV)需要使用特定选项重新编译目标。
尽管在处理二进制目标时重新编译不是一个选项,但是QEMU中仍然提供了一些这些功能
例如, AFL_USE_QASAN 可以使用 LD_PRELOAD 自动注入库来使用 ASAN 和 QEMU。同样, AFL_COMPCOV_LEVEL 可以在 QEMU 中使用 COMPCOV,无需重新编译目标。
下面的start_child用来启动子进程
1 | children=() |
1 | # Run 1 afl-fuzz instance with CMPLOG (-c 0 + AFL_COMPCOV_LEVEL=2) |
评估fuzzing
1 | $ /AFLplusplus/afl-whatsup -s output/ |
查看edges、crashes执行速度随实践变化的情况
1 | $ /AFLplusplus/afl-plot output/afl-main /tmp/plot |
通过afl-showmap输出覆盖情况
1 | "$afl_path/afl-showmap" -Q -C -i "$output_path"/afl-main/queue/ -o afl-main.cov -- "$target_path" /tmp/.afl_fake_input |
对于崩溃的文件
一旦AFL++识别出崩溃或卡死,它将把触发它的输入保存在您的输出目录中的一个专用文件夹中,以便您可以重现它。
下面是一些有用的工具:
- afl-tmin: 重现崩溃的最小测试用例
- Lighthouse: 探索特定样本的覆盖范围
- 使用Valgrind来调查内存问题;


